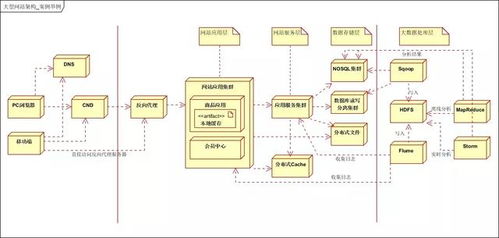
在大型分布式网站的复杂架构中,数据处理与存储支持服务是确保系统高可用、高性能、可扩展及数据一致性的基石。它们不仅负责海量数据的持久化,还支撑着实时计算、离线分析、缓存加速等关键业务场景。本文将对这一核心技术领域进行系统性。
一、 核心架构目标与挑战
在构建数据处理与存储服务前,必须明确其核心目标:
- 高可用性:服务需具备容错与故障自动转移能力,保证7x24小时不间断服务。
- 可扩展性:能够通过增加节点线性地提升存储容量与处理能力,以应对业务快速增长。
- 高性能:满足低延迟读写和高吞吐量的要求,支撑用户实时交互与后台批处理。
- 数据一致性:在分布式环境下,根据业务需求在强一致性、最终一致性等模型间做出合理权衡。
- 成本与运维效率:平衡性能与硬件成本,并保障系统的可监控性与可维护性。
主要挑战包括:数据分片策略、副本同步机制、跨数据中心数据同步、热点数据处理以及存储引擎的选型与优化。
二、 核心服务组件与技术选型
1. 结构化数据存储(SQL/NewSQL)
- 分库分表中间件:如ShardingSphere、MyCat,用于对传统关系型数据库(如MySQL)进行水平拆分,解决单库性能瓶颈。
- NewSQL数据库:如TiDB、CockroachDB,融合了NoSQL的分布式能力与SQL的事务特性,提供弹性伸缩与强一致性。
- 云托管服务:直接使用云厂商提供的RDS、Aurora等,降低运维复杂度。
2. 非结构化/半结构化数据存储(NoSQL)
- 键值存储:如Redis(内存)、DynamoDB,用于缓存、会话存储和高频读写场景。Redis集群模式支持数据分片与高可用。
- 文档数据库:如MongoDB、Couchbase,适合存储JSON格式的灵活模式数据,常用于内容管理、用户档案等。
- 宽列存储:如Cassandra、HBase,适合海量数据、高写入吞吐的场景(如时序数据、消息日志)。
- 搜索引擎:如Elasticsearch,专为全文检索与复杂聚合分析设计,常作为二级索引或日志分析平台。
3. 大数据存储与计算平台
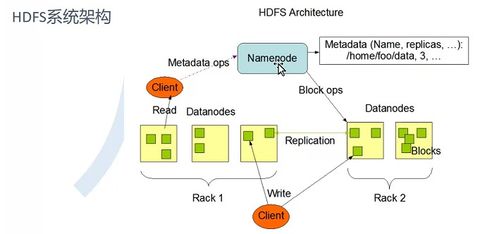
- 分布式文件系统:如HDFS、OSS/S3(对象存储),是海量冷数据或原始数据的存储底座。
- 数据仓库:如Hive、ClickHouse、Snowflake,用于离线大数据分析处理(OLAP)。
- 流处理平台:如Kafka(消息队列兼存储)、Pulsar,作为实时数据管道,连接在线服务与离线分析。
- 批流一体计算引擎:如Flink、Spark,在统一框架内处理实时流与历史批量数据。
4. 缓存服务体系
- 多级缓存架构:通常包含客户端缓存、CDN缓存、反向代理缓存(如Nginx)、应用层本地缓存(如Caffeine/Guava)以及分布式缓存(如Redis集群)。
- 缓存策略:合理运用缓存穿透、击穿、雪崩的应对方案,以及数据一致性策略(如旁路缓存、写穿透)。
5. 数据同步与复制服务
- 数据库主从复制:基于Binlog或WAL日志,实现读写分离与灾备。
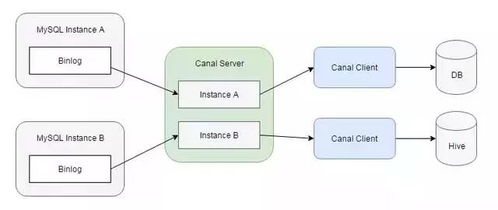
- CDC工具:如Debezium、Canal,捕获数据库变更并同步到搜索索引、数据仓库或缓存。
- 跨地域复制:利用存储系统自带能力(如Cassandra多数据中心支持)或通过消息队列异步同步,保障异地容灾。
三、 架构设计模式与最佳实践
- 读写分离与负载均衡:将写操作定向主库,读操作分散至多个从库或只读实例,通过代理或中间件实现。
- 数据分片策略:根据业务特性选择哈希分片、范围分片或列表分片,并考虑热点数据问题(如通过盐值散列)。
- CAP定理的权衡:根据业务场景选择CP型(如ZooKeeper,强调一致性)或AP型(如Cassandra,强调可用性)系统。大部分业务场景可接受最终一致性。
- 异构数据栈融合:不同存储引擎各司其职,通过数据同步管道(如Kafka Connect)构建统一数据视图,避免单一数据库“万能化”。
- 可观测性与治理:建立完善的监控体系(如Prometheus+Grafana),监控关键指标(QPS、延迟、错误率、存储容量);实施数据生命周期管理(冷热分层、归档删除)。
四、 未来趋势
- 云原生与Serverless数据库:数据库服务与容器化、Kubernetes编排深度集成,实现极致弹性与按需计费。
- 存算分离架构:计算节点与存储节点解耦,各自独立扩展,提升资源利用率和灵活性,已成为云上数据仓库的标准架构。
- AI驱动的智能运维:利用机器学习进行异常检测、性能调优与容量预测。
- 统一的数据湖仓:融合数据湖的灵活性与数据仓库的管理性能,在单一平台支持所有数据类型与分析负载。
###
大型分布式网站的数据处理与存储架构是一个持续演进、精心设计的复杂系统。成功的核心在于深刻理解业务需求,合理选择与组合多种技术组件,并遵循可扩展、高可用的设计原则。随着云原生与智能化的发展,未来的架构将更加弹性、自动化与成本高效,持续为上层业务提供坚实可靠的数据支撑。